

Improving reliability, stability and user experience with a serverless app using AWS Lambda and SQS
Improving reliability, stability and user experience with a serverless app using AWS Lambda and SQS
Implementing a queuing system for serverless workloads to provide a fast, responsive user experience and improve stability and reliability on the way.


A short while ago, I wrote about how I converted my Ruby on Rails application over to a serverless architecture reducing my need for running a server with a rails app, relational database and so forth. Something I completely forgot about was the side worker I had implemented using Sidekiq - a gem created to handle processing tasks. Given I was serving static content out of my S3 bucket, and the processing was a lambda that would be fired each time a user ran, I didn’t think that it would be a problem because of that distributed-by-default nature of the way that serverless works.
Problem
I found out quickly, after the app was running in production for a few days that the default timeout of API Gateway and was causing problems because for big lists, the processing lambda needed longer than the default timeout to process all the mail out of emails to the users. To solve with almost zero effort, I upped the timeout of API Gateway to the maximum value of 30 seconds, which was enough for lists of up to about 26-28. But it was a band-aid which was sure to become a problem later, if someone wanted to process a bigger list.
Approach
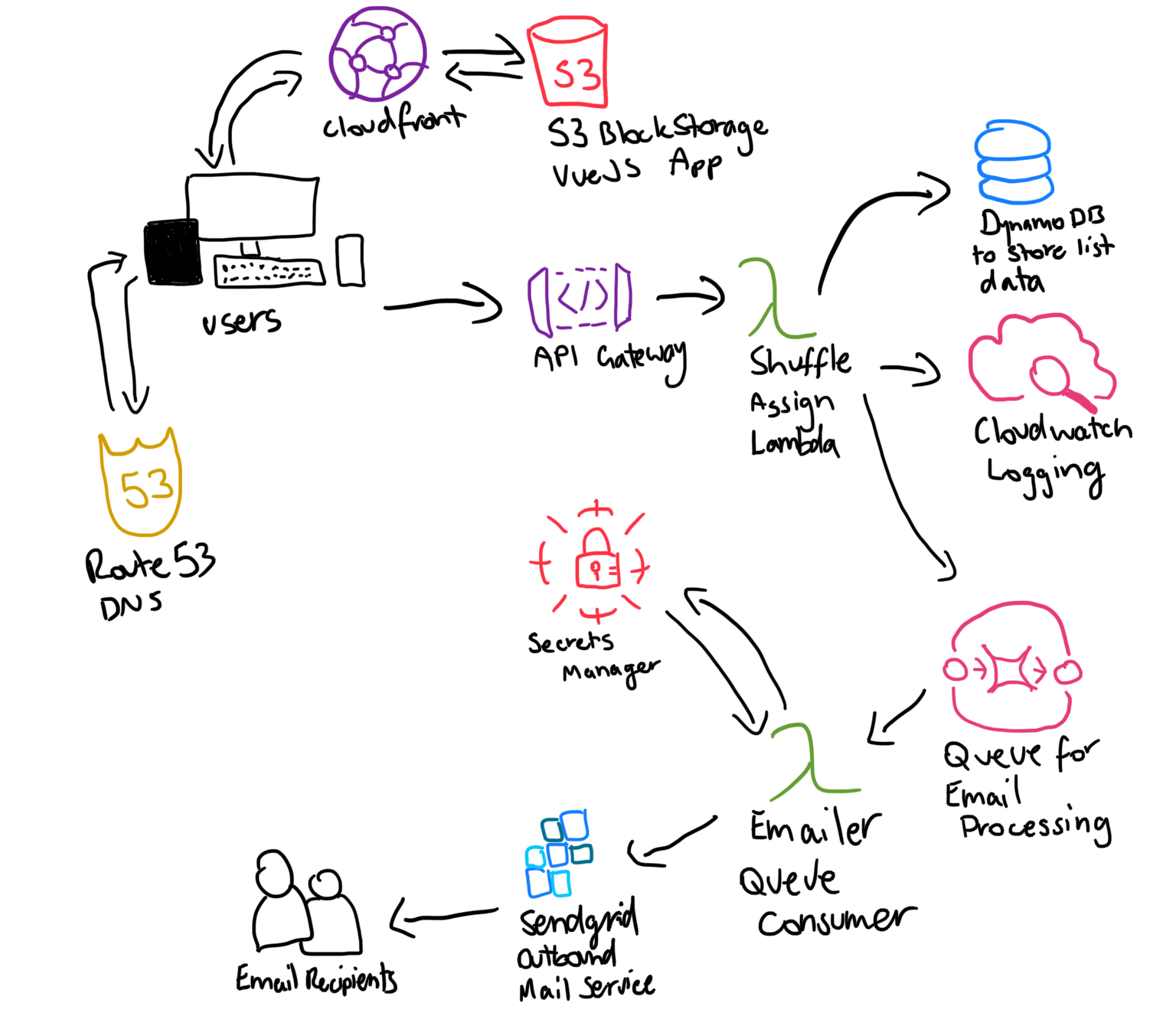
So to solve this, I decided to re-architect the app a bit to make use of a queuing system. Similar to the way it had originally worked in the Rails app with Sidekiq which used Redis as a pub/sub tool. In short, I re-wrote the lambda to publish a message to a queue which contained all the information in it needed to send an email to the user. Then another lambda reads messages off that queue and picks up to 10 at a time, and starts to process the messages.
So if we compare the previous drawing with the new architecture, we can see the implementation of a queue and another lambda which is the consumer. Additionally we can also see that only the lambda processing the messages needs to retrieve the secret as it’s the one connecting to the Sendgrid API.
Results
What was the result of this? Quite a number of good outcomes!
Improved stability. Much faster response times from the API. Since I was using the same region for all my infrastructure, it meant that internal calls to other AWS services were lightning fast! As a result the user is getting feedback from their form submission on the website much quicker.
Improved reliability. A single message is received by the lambda and then split into multiple messages, one for each user and then placed into the SQS queue. Then, each message is processed independently and a network call to the Sendgrid API is made. Should a call to the external service fail, then the message is retried up to 2 more times and then placed into a dead letter queue for further processing at a later date.
Better user experience. Because of the improved reliability and stability of the application, as well as it’s ability to handle more messages, I feel that the user experience is improved greatly. Users can send many more messages for users, the chance for errors is far lower and there are better methods in place to reduce the chance of failures and gracefully handle them, should they occur.
Fun Stats
Ok, but show me some stats, prove it! Fair point. For an experiment, I decided to “hammer” the endpoint with a single submission of 372 messages to see what would happen. How would the system scale?
API Gateway console, using the test feature, I fired a payload off.
Response in ~2 seconds (cold start)
372 messages in queue
Consuming lambdas (plural because multiple were fired to handle the load) picked up the max of 10 per retrieval from the queue.
Processed and sent to Sendgrid.
The whole thing happened in less than 5 seconds, I didn’t have enough time to see the messages showing in SQS because it was handled so quick.
Result: nearly 400 emails in my inbox.
